





Tesla V100计算卡免费送!英伟达迈向人工智能领域

英伟达的首席执行官黄仁勋最近在檀香山的计算机视觉与模式识别大会上,将最新款的基于Volta GPU的Tesla V100计算卡送给了排名前15位的人工智能研究机构。
英伟达以Tesla V100计算卡为基础重塑他们的人工智能研究
在这次活动中,英伟达的首席执行官不仅宣布了全新的由PCIe封装的特斯拉V100 PCIe计算卡,还将其交给了15位顶尖的人工智能研究人员。受到了150名来自15个不同人工智能研究机构的精英深度学习研究人员的热烈欢迎,并在英伟达人工智能实验室项目中展示了特斯拉V100 PCIe计算卡。
这张卡片被优雅地包装在一个黑色的盒子里,每个盒子里都有黄仁勋的签名,还有一个在计算卡的盒子上写着“做伟大的人工智能!”的题词。

NVIDIA Volta V100 GPU基于特斯拉V100 PCIe显卡封装,显示了在FP32精度下14 TFLOPs以及FP16精度下27 TFLOPs的浮点性能,TDP功耗为250瓦
英伟达在2017年的GTC发布了他们的基于Volta GPU的Tesla V100计算卡。英伟达的新芯片是一个庞然大物,利用了新一代的TSMC12nm的处理器,这是一种为NVIDIA的Volta gpu提供动力的定制芯片。
该芯片拥有令人难以置信的210亿个晶体管,这是一项了不起的工程技术。我们在GTC上看到的图形加速器使用了SXM2的形式,而NVIDIA则在使用一种基于PCI Express的变种。

NVIDIA Tesla V100用于一种基于PCI Express的系统,拥有与SXM2相同的伏塔V100 GPU。它的特点是GPU的大小为815mm2(迄今为止最大的芯片),并在主界面上存储了大量的HBM2存储器。让我们来运行一下核心参数。
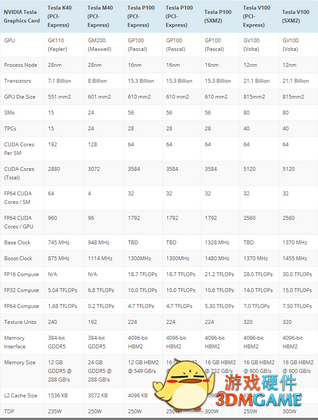
NVIDIA 基于Volta V100 GPU的特斯拉V100 PCI Express规格
芯片以全新的芯片架构为特色,在原始规格方面简直是疯狂的。NVIDIA Volta GV100 GPU由6个GPC(图形处理集群)组成。它总共有84个流媒体多处理器单元,42个tpc(每一个都包含两个SMs)。
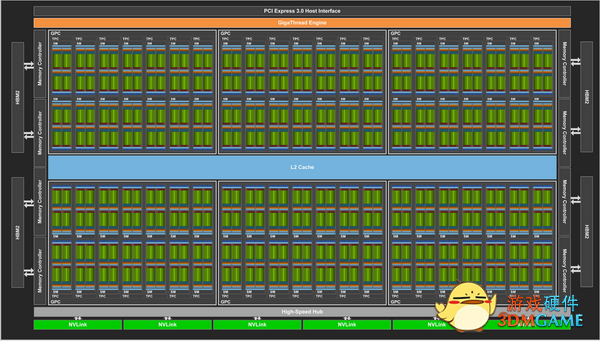
84个SMs,每个SM中有64个CUDA核心,所以我们总共看到了5376个CUDA核心。所有5376的CUDA核心都可以用于FP32和INT32编程指令,同时也有2688 FP64(双精度)核。除了这些,我们还看到了672个张量处理器,336个纹理单元。核心时钟保持在1370兆赫的boost时钟上,它提供了FP16的28 TFLOPs、FP32的14 TFLOPs和FP64的7.0 TFs的浮点性能。
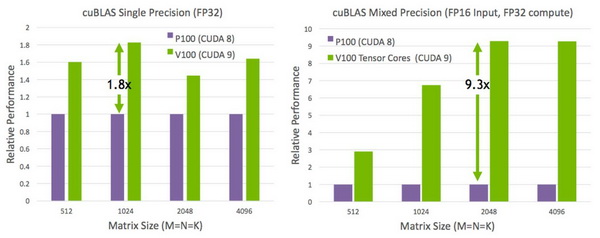
该芯片还提供112个DLOPs(深度学习Teraflops),这是迄今为止所有芯片中最快的。这是由专门用于深度学习任务的独立张量核来实现的。因此,虽然时钟和计算性能略低于SXM2,但它确实有一个TDP仅为250W。相比于SXM2卡上的300W,这是一个令人难以置信的壮举,它提高了效率。
内存架构用8个512位的内存控制器进行更新。这是一个4096位的总线接口,支持最多16 GB的HBM2 VRAM。带宽以878兆赫的速度提升,传输速率为900 gb/s,而在Pascal GP100上的传输速率为720 gb/s。每个内存控制器连接到768 KB的L2缓存,它为整个芯片提供了6 MB的L2缓存。
NVIDIA Tesla V100规格:
另一个不同之处是,特斯拉V100 PCI Express没有像基于SXM2的变种那样得到NVLINK支持。它配备了一个被动的双槽冷却机,这是之前看到的金色和黑色配色方案。与竞争对手相比,NVIDIA提供了更低的计算时间和更高的效率。
还需要指出的是,英伟达提供了双精度、单精度、半精度和高速率的产品,比竞争对手的发行卡要高得多。英伟达在人工智能领域做得很好,而Volta,他们才刚刚起步。现在,Volta GV100 GPU正在以SMX和PCIe的形式被运送到多个服务器上,并将很快为世界上最强大的超级计算机提供动力。
-
1想在《明日方舟:终末地》里畅快打灰需要准备些什么?
-
2AMD 锐龙9 9955HX与英特尔酷睿Ultra 9 275HX,谁才是玩家的“帧香”选择?
-
3华硕ROG B850迷你吹雪主板双12开售 纯白小钢炮
-
4把240p马赛克变4k的“NVIDIA神力”,发展到什么地步了?
-
5AMD 锐龙7 9850X3D首发评测:站在巨人的肩膀上更快更强
-
6索泰RTX 5080整机免费送!「无索不AI 桌搭大赛」正式开启
-
7R7000P和Y7000P怎么选?联想拯救者Y7000P 2025为何是更优选择?
-
8技嘉Z890 AORUS PRO ICE电竞冰雕评测:200S Boost模式加持,285K性能飞升
-
9“核力满满 帧帧制霸” AMD帧香电竞嘉年华南京终极一站完美谢幕,硬核性能引爆玩家狂欢!
-
10海信发布旗舰显示器GX:三大电视同源技术,新品首发价4399元



玩家点评 (0人参与,0条评论)
热门评论
全部评论